Qwen3-30B-A3B-Thinking-2507 Reasoning Model In-Depth Review
🎯 Key Takeaways (TL;DR)
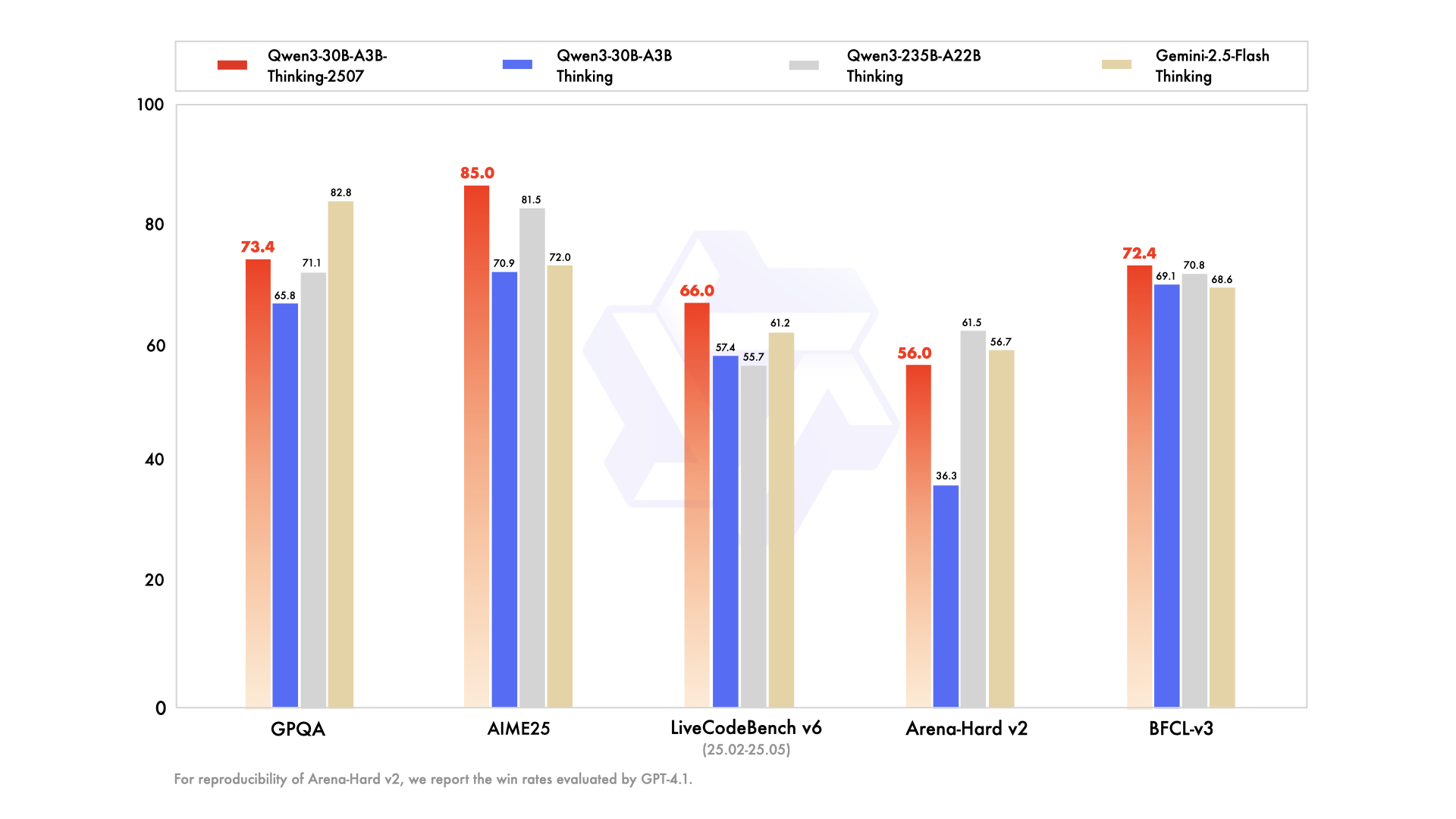
- Breakthrough Reasoning Capabilities: Qwen3-30B-A3B-Thinking-2507 achieves significant improvements in math, coding, and logical reasoning, scoring 85.0 on AIME25
- Local Deployment Friendly: Runs on 32GB RAM with quantized versions, achieving 100+ tokens/s on M4 Max
- Dedicated Reasoning Mode: Separated from non-reasoning version, specifically optimized for complex reasoning tasks with increased thinking length
- 256K Long Context: Native support for 262,144 tokens context length, suitable for complex document processing
- Active Community Support: Open-source community rapidly provides GGUF quantized versions with continuous tool compatibility improvements
Table of Contents
- What is Qwen3-30B-A3B-Thinking-2507
- Core Technical Features
- Performance Benchmarks
- Deployment & Usage Guide
- Real-World Testing Comparison
- Community Feedback & Discussion
- Frequently Asked Questions
Model Overview
Qwen3-30B-A3B-Thinking-2507 is the latest reasoning model released by Alibaba's Qwen team on July 30, 2025. Following the non-reasoning version Qwen3-30B-A3B-Instruct-2507, this represents Qwen team's official separation of reasoning and non-reasoning model lines.
💡 Important Change
Unlike previous hybrid reasoning modes, the new version adopts pure reasoning mode and no longer requires manual activation of the
enable_thinking=Trueparameter.
Technical Features
Model Architecture Details
| Feature | Specification |
|---|---|
| Total Parameters | 30.5B (3.3B activated) |
| Non-Embedding Parameters | 29.9B |
| Layers | 48 |
| Attention Heads | Q: 32, KV: 4 (GQA) |
| Number of Experts | 128 (8 activated) |
| Context Length | 262,144 tokens (native support) |
| Architecture Type | Mixture of Experts (MoE) |
Reasoning Mechanism Optimization
Reasoning Flow:
User Input → Auto-added <think> tag → Internal reasoning process → </think> tag → Final answer⚠️ Important Note
Model output typically only contains the
</think>tag, with the opening<think>tag automatically added by the chat template. This is normal behavior, not an error.
Performance Evaluation
Core Benchmark Comparisons
| Test Category | Gemini2.5-Flash-Thinking | Qwen3-235B-A22B Thinking | Qwen3-30B-A3B Thinking | Qwen3-30B-A3B-Thinking-2507 |
|---|---|---|---|---|
| Knowledge | ||||
| MMLU-Pro | 81.9 | 82.8 | 78.5 | 80.9 |
| MMLU-Redux | 92.1 | 92.7 | 89.5 | 91.4 |
| GPQA | 82.8 | 71.1 | 65.8 | 73.4 |
| Reasoning | ||||
| AIME25 | 72.0 | 81.5 | 70.9 | 85.0 |
| HMMT25 | 64.2 | 62.5 | 49.8 | 71.4 |
| LiveBench | 74.3 | 77.1 | 74.3 | 76.8 |
| Coding | ||||
| LiveCodeBench v6 | 61.2 | 55.7 | 57.4 | 66.0 |
| CFEval | 1995 | 2056 | 1940 | 2044 |
| OJBench | 23.5 | 25.6 | 20.7 | 25.1 |
✅ Performance Highlights
- Mathematical Reasoning: Achieves 85.0 on AIME25, surpassing Gemini2.5-Flash-Thinking
- Coding Capabilities: LiveCodeBench v6 score of 66.0, significant improvement
- Tool Usage: Excellent performance across multiple Agent benchmarks
Deployment Guide
System Requirements
# Basic Requirements
transformers >= 4.51.0
torch >= 2.0
# Recommended Configuration
- GPU: 24GB+ VRAM (full precision)
- RAM: 32GB+ (quantized version)
- Storage: 60GB+Quick Start Code
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Thinking-2507"
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# Prepare input
prompt = "Explain how large language models work"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# Generate response
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
# Parse thinking content
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:
index = len(output_ids) - output_ids[::-1].index(151668) # </think> token
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True)
final_answer = tokenizer.decode(output_ids[index:], skip_special_tokens=True)
print("Thinking process:", thinking_content)
print("Final answer:", final_answer)Deployment Options Comparison
| Deployment Method | Advantages | Use Cases | Command Example |
|---|---|---|---|
| SGLang | High-performance inference | Production | python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Thinking-2507 --reasoning-parser deepseek-r1 |
| vLLM | Batch processing | API services | vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507 --enable-reasoning --reasoning-parser deepseek_r1 |
| Ollama | Local usage | Personal development | ollama run qwen3:30b-a3b-thinking-2507 |
| LM Studio | GUI interface | Desktop applications | GUI operation |
Real-World Testing
SVG Generation Test
Test Prompt: "Generate an SVG of a pelican riding a bicycle"
Reasoning Version Results:
- Detailed reasoning process considering component positions and proportions
- Final SVG output quality was poor, with unreasonable element arrangement
- Looked like a "grey snowman" rather than a pelican
Non-Reasoning Version Results:
- Direct generation with better quality
- Included cute details like the pelican's smile
- Overall layout was more reasonable
🤔 Interesting Finding
In creative tasks, reasoning mode doesn't always produce better results. Excessive reasoning might actually hinder creative output.
Programming Task Test
Test Prompt: "Write an HTML and JavaScript page implementing space invaders"
Reasoning Version Performance:
- ✅ Game runs properly
- ✅ More detailed enemy design (eyes, antennae, etc.)
- ❌ Game balance needs improvement (low enemy firing rate)
Non-Reasoning Version Performance:
- ❌ Game has runtime issues (excessive speed)
- ❌ Basic functionality incomplete
✅ Clear Reasoning Advantage
In complex programming tasks, reasoning mode significantly improves code completeness and usability.
Community Insights
Reddit LocalLLaMA Community Feedback
Positive Reviews:
"This is basically a GPT-4 level model that runs (quantized) on a 32gb ram laptop. Yes it doesn't recall facts from training material as well but with tool use (e.g. wikipedia lookup) that's not a problem and even preferable to a larger model."
"Your speed and reliability, as well as quality of your work, is just amazing. It feels almost criminal that your service is just available for free."
Technical Discussions:
Community users reported chat template compatibility issues:
- Original template couldn't properly parse
<think>tags in certain tools - Unsloth team responded quickly, re-uploading fixed GGUF files
- Solution: Remove
<think>tag from chat template since model generates it ~100% of the time
Hacker News Technical Discussion
Performance Data:
- Running MLX 4bit quantized version on M4 Max 128GB
- Small context: 100+ tokens/s
- Large context: 20+ tokens/s
Use Cases:
"This model is truly the best for local document processing. It's super fast, very smart, has a low hallucination rate, and has great long context performance (up to 256k tokens). The speed makes it a legitimate replacement for those closed, proprietary APIs that hoard your data."
Model Comparisons:
- In spam filtering benchmarks, only surpassed by Gemma3:27b-it-qat
- But Qwen3 is much faster, more suitable for real-time applications
Simon Willison's In-Depth Testing
Test Conclusions:
- Creative Tasks: Reasoning version performs worse than non-reasoning version in creative tasks like SVG generation
- Programming Tasks: Reasoning version clearly outperforms non-reasoning version in complex programming tasks
- Model Positioning: Reasoning and non-reasoning versions each have advantages; choose based on task type
Best Practices
Recommended Parameter Settings
# Sampling parameters
generation_config = {
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20,
"min_p": 0.0,
"presence_penalty": 1.0, # Reduce repetition
"max_new_tokens": 32768, # General tasks
# "max_new_tokens": 81920, # Complex reasoning tasks
}Task-Specific Optimization
| Task Type | Recommended Settings | Prompt Suggestions |
|---|---|---|
| Math Problems | max_tokens=81920 | "Please reason step by step, and put your final answer within \boxed{}" |
| Multiple Choice | max_tokens=32768 | "Please show your choice in the answer field with only the choice letter, e.g., \"answer\": \"C\"" |
| Programming | max_tokens=81920 | "Please provide complete runnable code with error handling" |
| Document Analysis | max_tokens=32768 | "Please analyze based on the provided document content" |
Multi-turn Conversation Notes
⚠️ Important Reminder
In multi-turn conversations, history should only include the final output part, not the thinking content. This helps:
- Reduce token consumption
- Improve conversation coherence
- Avoid reasoning process interference
🤔 Frequently Asked Questions
Q: Why does the model output only </think> without <think>?
A: This is normal behavior. The chat template automatically adds the opening <think> tag, and the model only needs to output the closing tag. If you encounter parsing issues in certain tools, you can modify the chat template to remove the <think> tag.
Q: How should I choose between reasoning and non-reasoning versions?
A:
- Choose Reasoning Version: Complex math, programming, logical reasoning, multi-step problems
- Choose Non-Reasoning Version: Creative writing, quick Q&A, simple tasks, conversational chat
- Performance Consideration: Reasoning version requires more computational resources and time
Q: Is there significant performance loss with quantized versions?
A: According to community testing, Q4_K_M quantized versions maintain good performance on most tasks, but we recommend:
- Use Q8_0 or higher precision for critical applications
- Use Q4_K_M for resource-constrained environments
- Avoid excessive quantization (below Q3)
Q: How to handle OOM (Out of Memory) issues?
A:
- Reduce context length: From 262144 to 131072 or lower
- Use quantized versions: Choose appropriate quantization level
- Layer-wise loading: Use
device_map="auto"for automatic allocation - Batch optimization: Reduce batch_size
Q: Which languages does the model perform best on?
A: According to benchmark tests, the model excels in multilingual tasks:
- Chinese: Native support, best performance
- English: Near-native level
- Other Languages: Verified through MMLU-ProX and INCLUDE tests, supports multiple languages
Summary and Recommendations
Qwen3-30B-A3B-Thinking-2507 represents significant progress in open-source reasoning models. Its main advantages include:
✅ Technical Breakthrough: Reaches new heights in mathematical and programming reasoning
✅ Deployment Friendly: Suitable for local deployment with reasonable resource requirements
✅ Community Support: Active open-source community with comprehensive tool ecosystem
✅ Professional Focus: Dedicated to reasoning tasks, avoiding hybrid mode complexity
Immediate Action Items
- Assess Needs: Choose reasoning or non-reasoning version based on application scenarios
- Test Deployment: Start with quantized versions to verify performance
- Optimize Configuration: Adjust parameter settings based on task types
- Stay Updated: Follow community feedback and model updates
Related Resources
This article is compiled based on information as of July 31, 2025. Models and tools may continue to be updated. Please follow official channels for the latest information.